Porting Burst to the New LLVM Pass Manager
Last week the Burst team shook up our day-to-day schedules with the opposite of a Unity classic - the hackweek. Unity has a strong culture around taking a week or two a year (once with the whole company, maybe once with your team), to hack on something that you think might be an interesting avenue for the future of Unity. These projects have often been spun out into products or parts of products in their own right.
But what about the opposite of hacking - what about spending some time consolidating what is currently there and working on the things that you really think will benefit the product over all, but haven’t had the time to work on. We did exactly that last week.
One thing that has been bugging me since LLVM 12 landed was that we were still using the legacy pass manager, which was the default optimization pipeline for LLVM for every release prior to LLVM 12. But in LLVM 12 they finally, after about 7 years since I first heard about the new pass manager, pulled the trigger and switched the default pipeline over. Since the legacy pass manager is still in the codebase (it is still actually being used at present to power the backend infrastructure), we didn’t have to use the new one with Burst. But the writing is clearly on the wall for the legacy pass manager, and I’ve heard and read claims that the new pass manager does some things better than the legacy one, maybe meaning faster compilation or better codegen.
So TL;DR I’ve added the new pass manager support to Burst, and here is a brain dump of how I went about it incase there is anyone else wanting to attempt the feat - hopefully you can avoid a few of the landmines I trod on!
Porting Over a Pass⌗
The first thing is - how do you port a pass over from the legacy pass manager to the new one. Keep in mind that our code with Burst has to support LLVM 8..12 at present (for various platform reasons), so all my passes must work with the legacy pass manager and the new one concurrently, in the same codebase. I’d argue that you should do this approach anyway even if you want to abandon the legacy pass manager because:
- While porting both the legacy and the new pass manager code should work in the same codebase, letting you A/B test the changes for any regressions.
- Also lets you do performance profiling between the pass managers too.
- Even after landing you might yet find some corner case in the new pass manager that is broken and need to switch back to the old approach.
So let’s take one of our custom passes in Burst - a pass that does a much more extensive job of removing dead loops from the code. We need this pass because we found a bunch of cases where vectorization was blocked by a dead inner loop. The pass structure looked like:
struct DeadLoopRemovalPass final : public llvm::FunctionPass
{
DeadLoopRemovalPass() : llvm::FunctionPass(ID) {}
bool runOnFunction(llvm::Function& function) override;
void getAnalysisUsage(llvm::AnalysisUsage& analysisUsage) const override;
llvm::StringRef getPassName() const override { return "Burst Dead Loop Removal"; }
static char ID;
};
char DeadLoopRemovalPass::ID;
So I first looked at how LLVM did the dual support for legacy/new pass managers. Their general overall approach is one of two ways:
- Either they have a wrapper around the new pass manager structure, providing the same code to the legacy pass manager.
- Or they have a shared class that both the legacy/new pass managers will use.
I decided to use the latter approach, for no reason other than it seemed easier to port over to.
The Implementation Struct⌗
To do this I first removed the dependency of the struct above on the legacy llvm::FunctionPass, and made it a standalone struct:
struct DeadLoopRemoval final
{
explicit DeadLoopRemoval() {}
bool run(
llvm::Function& function,
std::function<llvm::LoopInfo& ()>,
std::function<llvm::DominatorTree* ()>,
std::function<llvm::PostDominatorTree* ()>) const;
static llvm::StringRef getPassName() { return "Burst Dead Loop Removal"; }
};
Which entailed:
- Removing the inherit from
llvm::FunctionPass. - Removing the
static char ID. - Morphing
runOnFunction->run, and passing in callbacks to retrieve the analysis information I required to implement the pass. I changed the name fromrunOnFunction->runjust so that it gave me compile errors at the callsite as I was porting so I could find everything. Also note theoverridedisappears from the function because we have no abstract virtual function to overload. - Changed
getPassName()to be a static function and removed theoverride. The new pass manager uses a static pass name retriever whereas the old used a virtual member function - so this allows us to support both.
The Legacy Wrapping Pass⌗
Then before I even touched the new pass manager, I implemented the original pass for the legacy pass manager again, but making it just wrap the logic of the pass from the new DeadLoopRemoval struct:
struct DeadLoopRemovalLegacyPass final : public llvm::FunctionPass
{
DeadLoopRemovalLegacyPass() : llvm::FunctionPass(ID) {}
bool runOnFunction(llvm::Function& function) override
{
if (skipFunction(function))
{
return false;
}
auto getLI = [&]() -> llvm::LoopInfo&
{
return getAnalysis<llvm::LoopInfoWrapperPass>().getLoopInfo();
};
auto getDT = [&]() -> llvm::DominatorTree*
{
llvm::DominatorTreeWrapperPass* const dominatorTreeWrapperPass =
getAnalysisIfAvailable<llvm::DominatorTreeWrapperPass>();
return dominatorTreeWrapperPass ?
&dominatorTreeWrapperPass->getDomTree() :
nullptr;
};
auto getPDT = [&]() -> llvm::PostDominatorTree*
{
llvm::PostDominatorTreeWrapperPass* const postDominatorTreeWrapperPass =
getAnalysisIfAvailable<llvm::PostDominatorTreeWrapperPass>();
return postDominatorTreeWrapperPass ?
&postDominatorTreeWrapperPass->getPostDomTree() :
nullptr;
};
return pass.run(function, getLI, getDT, getPDT);
}
void getAnalysisUsage(llvm::AnalysisUsage& analysisUsage) const override
{
// We need loop analysis to replace our intrinsics.
analysisUsage.addRequired<llvm::LoopInfoWrapperPass>();
analysisUsage.addPreserved<llvm::LoopInfoWrapperPass>();
// We will use the dominator tree, and preserve it during this pass. We
// do this because recalculating the dominator tree after this pass was
// much more expensive than just preserving it.
analysisUsage.addPreserved<llvm::DominatorTreeWrapperPass>();
analysisUsage.addPreserved<llvm::PostDominatorTreeWrapperPass>();
}
llvm::StringRef getPassName() const override { return DeadLoopRemoval::getPassName(); }
static char ID;
private:
DeadLoopRemoval pass;
};
char DeadLoopRemovalLegacyPass::ID;
So this code is pretty straight-forward, I started with a copy-paste of the original pass and then started hacking it to use the new struct underneath:
- I first added the
DeadLoopRemoval passmember to the struct. - Then I forwarded the
getPassName()member virtual function to the static method in the implementing struct. - For the
runOnFunctionbody I had to query the analysis passes I required in the lambdas, and pass these to thepass.runmethod.
At this point I can test the ported pass with our existing test suite and the legacy pass manager, to ensure that worked before doing anything else. And it did! So next up, lets port it to the new pass manager.
The New Wrapping Pass⌗
The new pass manager uses a mixin approach with the Curiously Recurring Template Pattern (CRTP, we’ll come back to this) to implement the structure. This means no virtuals, no overrides, but there is still a specific function you are expected to provide. For a function pass you implement llvm::PreservedAnalyses run(llvm::Function&, llvm::FunctionAnalysisManager&) for instance. Our new pass manager wrapping pass thus looks like:
struct DeadLoopRemovalPass final : public llvm::PassInfoMixin<DeadLoopRemovalPass>
{
explicit DeadLoopRemovalPass() : pass() {}
llvm::PreservedAnalyses run(llvm::Function& function, llvm::FunctionAnalysisManager& analysisManager)
{
auto getLI = [&]() -> llvm::LoopInfo&
{
return analysisManager.getResult<llvm::LoopAnalysis>(function);
};
auto getDT = [&]() -> llvm::DominatorTree*
{
return analysisManager.getCachedResult<llvm::DominatorTreeAnalysis>(function);
};
auto getPDT = [&]() -> llvm::PostDominatorTree*
{
return analysisManager.getCachedResult<llvm::PostDominatorTreeAnalysis>(function);
};
if (pass.run(function, getLI, getDT, getPDT))
{
llvm::PreservedAnalyses preserved;
preserved.preserve<llvm::LoopAnalysis>();
preserved.preserve<llvm::DominatorTreeAnalysis>();
preserved.preserve<llvm::PostDominatorTreeAnalysis>();
return preserved;
}
else
{
return llvm::PreservedAnalyses::all();
}
}
static llvm::StringRef name() { return DeadLoopRemoval::getPassName(); }
private:
const DeadLoopRemoval pass;
};
Digging into this:
- Our pass derives from
llvm::PassInfoMixin<DeadLoopRemovalPass>, taking itself as the template argument (the CRTP paradigm). - We have an implementation of the
runmethod like I stated above. - We use the explicit
analysisManagerto get the analysis passes we require, rather than using thegetAnalysisthat the old pass manager used to get at these. - We do not return a true/false value from our
runmethod like the legacy pass managerrunOnFunction. True meant ‘something changed, analysis passes might be invalid!’. For the new pass manager we explicitly return anllvm::PreservedAnalyseswhich we add what passes we preserved into. - Also note the
static llvm::StringRef name()method - this is how you set the pass name of the pass.
And that’s it! We now have our pass working both with the new and legacy pass managers. I had to do this same approach with all 20 of our custom LLVM passes, quite a lot of typing, but meant I could be sure at each step it was doing the right thing.
Porting Our Custom Pass Pipeline⌗
We long since abandoned the default LLVM pass pipeline for a custom one.
As an aside my COVID cancelled LLVM talk was going to explain how we cut the cost of using
llvm::PassManagerBuilder’s default optimization pass structure by 40% by cutting out the cruft from it while still using the builder, but even that wasn’t enough control for us to get the abosolute best compile time possible.
So our legacy pass manager usage involved us calling each of the LLVM passes (a mix of the standard ones and our custom ones, hand crafted for best codegen and compile time):
mpm.add(burst_CreateEarlyMemOptsLegacyPass());
if (optLevel >= 1)
{
mpm.add(llvm::createCFGSimplificationPass());
mpm.add(llvm::createSROAPass());
mpm.add(llvm::createEarlyCSEPass());
}
if (optLevel >= 3)
{
mpm.add(llvm::createIPSCCPPass());
mpm.add(llvm::createGlobalOptimizerPass());
}
This is just a sample from the pass pipeline, but it gives you an idea I hope.
For the new pass pipeline I did the obvious (and wrong) thing of copying that and changing it to the new pass manager:
burst_AddEarlyMemOptsPass(mpm);
if (optLevel >= 1)
{
mpm.addPass(llvm::SimplifyCFGPass());
mpm.addPass(llvm::SROA());
mpm.addPass(llvm::EarlyCSEPass());
}
if (optLevel == 3)
{
mpm.addPass(llvm::IPSCCPPass());
mpm.addPass(llvm::GlobalOptPass());
}
I did this for our entire pass pipeline, Visual Studio showed no errors! I hit compile, and explosions. It took me longer than I’d care to admit to work out what the issue was - the new pass manager requires you to add a pass to the correct pass manager type.
With the legacy pass manager everything derived from llvm::Pass, including llvm::ModulePass and llvm::FunctionPass. Behind the scenes the pass manager would work out that you were using a function or module pass, and behind your back create a manager of the correct type (so if you used a function pass, it’d make a function pass manager for you). This is a bad design, and so with the new pass managers they changed it.
Remember the CRTP thing I mentioned above? This is where it really hurts developers - Visual Studio didn’t provide me with compile errors until I actually did a full compile, because the CRTP is basically an interface that requires all the templates to be instantiated with their implementing types, before it can work out you’ve done the wrong thing. This shows up two bad bits of C++ - no interfaces (C# interfaces are so very nice for exactly this kind of issue), and templates nearly always result in horrific error messages. Very user hostile!
Because its been an easy 6 years since I last looked at the new pass manager (I honestly figured it would just die after such a long stint in the codebase but not being used by Clang), I took a look at the llvm::PassBuilder which helped me work out my mistake:
{
llvm::FunctionPassManager fpm;
burst_AddEarlyMemOptsPass(fpm);
if (optLevel >= 1)
{
fpm.addPass(llvm::SimplifyCFGPass());
fpm.addPass(llvm::SROA());
fpm.addPass(llvm::EarlyCSEPass());
}
mpm.addPass(llvm::createModuleToFunctionPassAdaptor(std::move(fpm)));
}
if (optLevel == 3)
{
mpm.addPass(llvm::IPSCCPPass());
mpm.addPass(llvm::GlobalOptPass());
}
So you can see I had to explicitly make an llvm::FunctionPassManager, add the function passes to that, and then call llvm::createModuleToFunctionPassAdaptor to provide this function pass to the surrounding module pass manager. A bit verbose, and horrific template mess aside, a much much better design overall. This makes it really obvious now when you are mixing function pass managers with module passes in a poor way, because you have to re-create the function pass manager each time.
More explicit is always a win in my book.
Another thing that got me was that you have to manually register all the analysis passes you need with the analysis managers explicitly:
llvm::PassBuilder& pb; // an already created pass builder
llvm::LoopAnalysisManager lam;
pb.registerLoopAnalyses(lam);
llvm::FunctionAnalysisManager fam;
fam.registerPass([&] { return llvm::TargetIRAnalysis(targetMachine->LLVM->getTargetIRAnalysis()); });
fam.registerPass([&] { return llvm::TargetLibraryAnalysis(targetLibraryInfo); });
llvm::AAManager aam;
aam.registerFunctionAnalysis<llvm::BasicAA>();
if (optLevel == 3)
{
aam.registerFunctionAnalysis<llvm::ScopedNoAliasAA>();
}
if (optLevel >= 2)
{
burst_AddExtraAliasAnalysisPass(fam, aam);
}
fam.registerPass([aam] { return std::move(aam); });
pb.registerFunctionAnalyses(fam);
llvm::CGSCCAnalysisManager cgam;
pb.registerCGSCCAnalyses(cgam);
llvm::ModuleAnalysisManager mam;
pb.registerModuleAnalyses(mam);
pb.crossRegisterProxies(lam, fam, cgam, mam);
Here I created an llvm::PassBuilder not to actually build the passes, but to build the analysis managers so that the analysis passes I required are available in the managers. There are some quirks:
- To provide an analysis to the analysis manager you pass in a callback that creates the pass. Note sure why this is needed (maybe have to delay the initialization?), but it confused me at the beginning!
- To register our custom alias analysis we had to add that to a
llvm::AAManager, and then register that with our function analysis manager. - You need to call
crossRegisterProxieson the pass builder to make sure all the analysis managers know about each each (in the case that, say, a function requires a module-level analysis).
The Curious Case of the Optimized optnone Functions⌗
LLVM IR has a function level attribute optnone that disables optimization for a specific function. This is really useful for developers when they suspect there is a bug in a specific function, so they can just disable the optimizations there and work out what is going wrong more easily. When I ran our tests with the new pass manager, I noticed that our optimize none tests were… being optimized?! The functions have optnone on them, how could the pass manager be allowing them to be optimized?
In the legacy pass manager each pass has a skipFunction call on it that tells you if you should skip running on that function. If optnone was set, you’d skip that function. The new pass manager of course doesn’t use this mechanism and does something entirely different. Obviously.
llvm::PassInstrumentationCallbacks passInstrumentationCallbacks;
llvm::OptNoneInstrumentation optNoneInstrumentation(false);
optNoneInstrumentation.registerCallbacks(passInstrumentationCallbacks);
llvm::PassBuilder pb(targetMachine->LLVM, llvm::PipelineTuningOptions(), llvm::None, &passInstrumentationCallbacks);
You have to register an llvm::OptNoneInstrumentation with a llvm::PassInstrumentationCallbacks, which is then registered in the llvm::PassBuilder constructor. I need to lie down. This then ensures that any function with optnone won’t be optimized through some arcane process I don’t really understand.
The Performance⌗
I’ve long been told that the new pass manager will result in better performance because of how analysis passes are preserved better. So I was excited to run our tests for the first time.
First up the compile time performance:
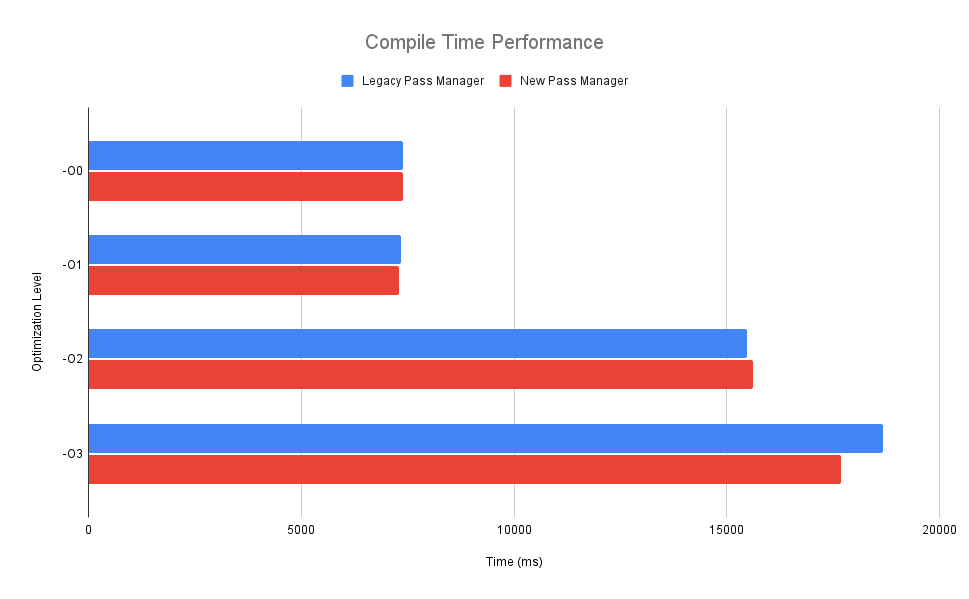
I’ve got to admit - after first running this I was a little disappointed - the new pass manager was meant to magically make everything faster! Then after I calmed down a bit I realised - this is fine. Since we’ve already got our own custom curated set of passes that are ordered specifically to not trash analysis passes unnecessarily, it stands to reason that we wouldn’t see any magical uplift with the new pass manager. The fact we are seeing numbers that are effectively within the signal-to-noise of each other means that when we do switch to the new pass manager by default, things won’t instantly go slower as a result. That’s a win.
Now for the binary size:
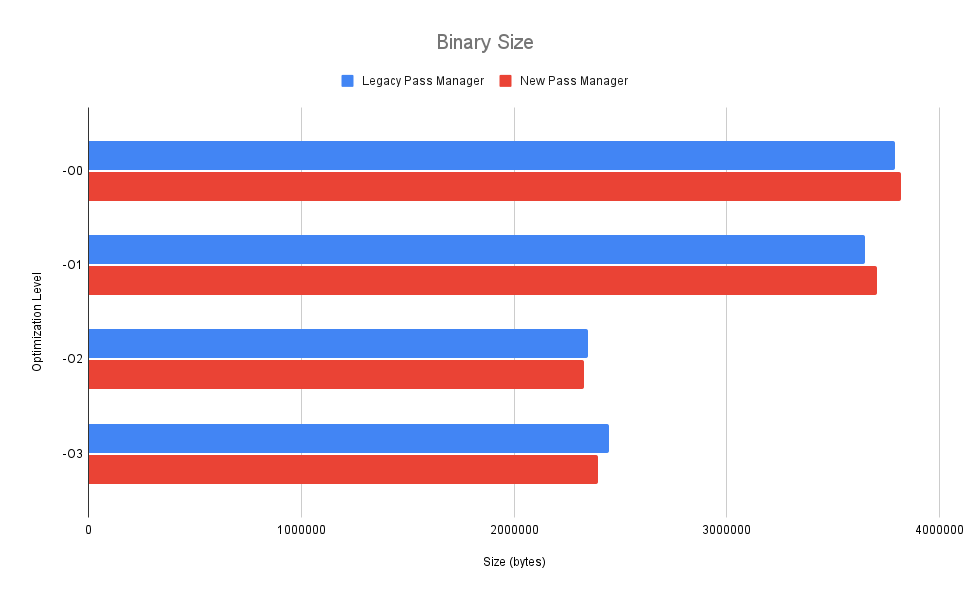
Nothing really to write home about here - slightly higher with -O0 and -O1, and slightly lower with -O2 and -O3. I did a diff of the assembly and its just the usual slight reordering of passes - mostly the same instructions just sometimes in a different order. Again, this is good though - no regressions means we can safely make the switch.
One Last Pain Point⌗
One thing I generally like to do on Windows is use a RelWithDebInfo compiled LLVM with a Debug or Release compiled our code. This gets me the best of both worlds in terms of some debuggability while not running dreadfully slow. For some reason while this has always worked with the legacy pass manager, someone in the LLVM community has added a bunch of:
#ifndef NDEBUG
// Some extra struct state!
#endif
To some of the new pass manager structs.
They are doing this so that on debug builds they can carry around some extra state in the structs to aid debuggability, but this means that the struct layout is now different between Debug and Release builds. This is absolutely awful, and means my RelWithDebInfo compiled approach no longer works. This took me 4 hours to narrow down - I just assumed some of the template mess in the new pass manager was somehow going wrong, it was only when I started printing the size of structs that my head hit the desk. I hope someone can remove these - I’d rather carry around the extra state always and not use it, than have structs change size depending on the optimization level.
Conclusion⌗
This work took me a week to do for our reasonably customized LLVM pass pipeline and custom passes. It is a lot of boiler plate for something that effectively does the same as before, but it does set us up more cleanly for the day that LLVM actually removes the legacy pass manager from the codebase entirely, meaning that when that day comes we aren’t floundering. The new pass manager has some nice features, it is just a shame that C++ is so broken as a language that it takes walking through a wall of template errors to work out what went wrong.
And before anyone @’s me - I know concepts will in theory fix this, just colour me highly skeptical on that count.
Until next time!