1.22x Performance Improvements in json.h!
I’ve been meaning to try out Intel’s VTune now that it has a permanent trial mode (you can renew the 30-day trial license every 30-days without paying!), as I’ve long heard people rave about it as a profiling aid. I decided to pick one of my open source C libraries and see what performance problems I could find in the code, and I choose my JSON parser json.h.
I’ve long known that the recursive approach I used in the parser will limit the performance I can get out of the code as compared to some of my competitors, but I support a metric-ton of extensional functionality (simplified JSON and JSON5 to name two major extensions that my users love). That being said, while I wasn’t in the mood to replace my recursive strategy with a more optimal looping variant, I did want to see if there were any easy wins to be had in the code.
I decided to use the large citylots.json test file as my benchmark file, and parsed the file twice just to ensure enough work was done to get some good sampling results.
The initial run took 3.106s, averaging 116.5 MB/s throughput. With that baseline, I dived into VTune.
Initial VTune Results⌗
So I compiled my JSON library using CMake’s RelWithDebInfo (release with debug info) so that PDBs were generated from Visual Studio and I could get meaningful profiling information.
Then I started VTune, added an Analysis Target pointing at my executable, and not knowing a great deal about VTune decided to stick with an Analysis Type of Basic Hotspots and see where that took me.
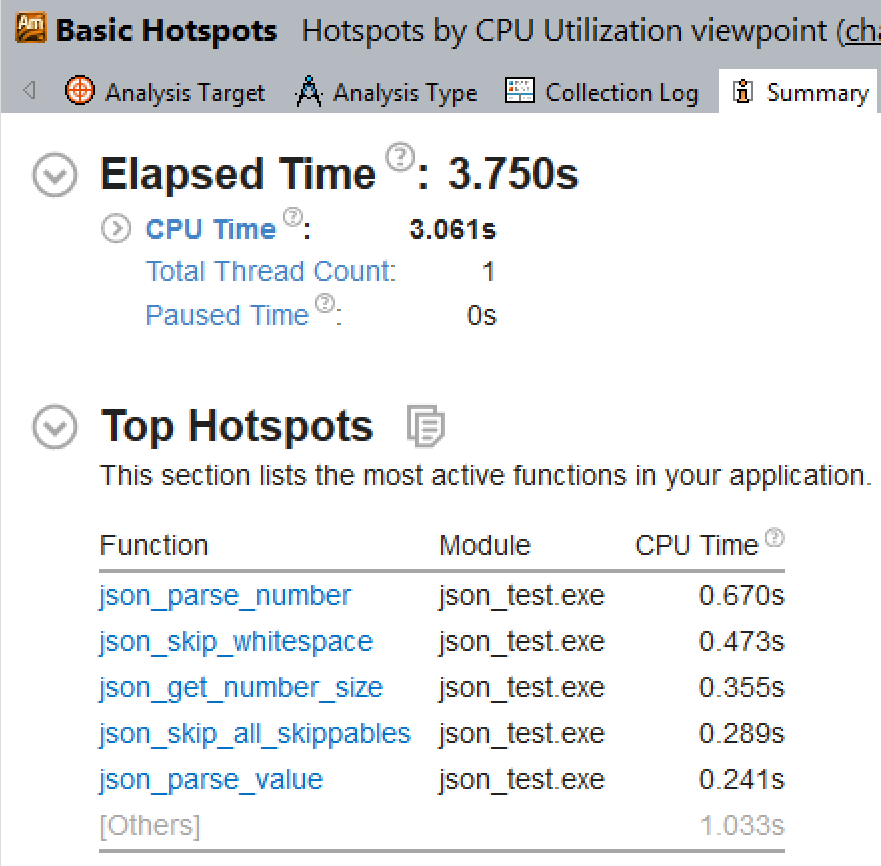
So VTune says that my CPU time was 3.061s (which matches closely to what I recorded out-with VTune), and has noted the most costly functions in terms of execution time. So I went to the source of the most expensive function there, and looked at the assembly view that VTune gives you, and I found something bad, something very bad!
Can you notice what heinous crime I have committed? Lets look at the assembly as captured from VTune for the switch statement above:
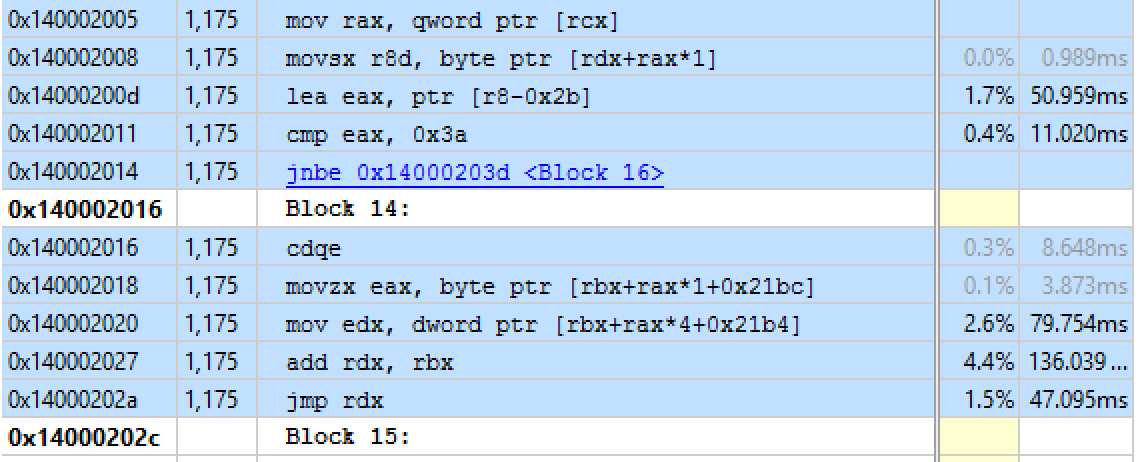
Now its not obvious from the switch statement, but every execution of that switch is actually performing two loads, every iteration of the loop. Why? Because the compiler doesn’t realise that state->offset cannot be modified outwith the function, and thus it could just cache the value of it into a register and use that!
This is the kind of dumb optimization that it is so easy to miss but so painful for performance when you do miss it. I reworked the code above such that:
And this changed reduced the time in json_parse_number from 0.670s to 0.422s - 1.59x faster!
Using The Same Trick Elsewhere⌗
Given the big performance win that helping the compiler realise state can live in registers got me, I decided to propagate the change into some other JSON functions that had tight inner loops that would most benefit from the same improvement:
- json_get_number_size from 0.355s to 0.184s - 1.93x faster
- json_get_string_size from 0.175s to 0.115s - 1.52x faster
- json_parse_string from 0.191s to 0.137s - 1.39x faster
- json_skip_whitespace from 0.473s to 0.354s - 1.34x faster
Nice little win with a single optimization trick right there.
Two Loops Are Better Than One⌗
The next function that caused me concern was json_skip_all_skippables. This jankily named function will skip whitespace and C-style comments if the user has enabled the C-style comment optional extension.
When I checked in VTune I noticed that the if branch within the do/while loop was taking more time than it should, and I suddenly realised - the compiler was reloading state->flags_bitset every iteration of the loop because the compiler does not know that this value will never change during parsing! Big doh moment here. To fix this, I moved the if statement outside the loop, and instead had two separate loops, one that handled C-style comments and one that did not. This simple change meant that json_skip_all_skippables went from 0.289s to 0.257s - a 1.12x speedup!
Help a Branch Out⌗
Sometimes branches can confuse a compiler, and json_parse_number had a doozy of a branch.
The switch statement should break out of the switch and the while when it is hit, so to do this I set end to 1, and then checked end == 0 in the loop condition. The compiler wasn’t smart enough to skip the end == 0 check on the first iteration for starters, and then it really managed to confuse itself on subsequent iterations. To fix this, I moved the end variable into the loop, and then after the switch statement I check if we’ve to end and break the main loop.
This subtle change meant much better generated code, and shaved a couple of milliseconds off of json_parse_number!
Remove a Useless Ternary⌗
In json_parse_string I support the quoting of strings by either using single (‘) or double (“) quotes - depending on an extension flag. The code was:
The optimizer got very confused by the is_single_quote ternary being in the while loop. Given that the quote to use won’t be changing iteration to iteration of the loop, I did the simple change to store the quote to compare against at the head of the loop instead:
I also noticed that if a string begins, it will definitely have at least one iteration in the body of it (otherwise when we earlier called json_get_string_size it would have exited with an error for the user). This meant that I could change the while loop to a do/while loop which aids the codegen too. These changes shaved another few milliseconds off of the execution time.
Cache More Things!⌗
I took stock of where I had got to, and decided to do a second sweep of each of the most costly functions to see if there was something I had missed - and of course there was. So previously I had cached just the offset and size from the state object I pass between functions, but I soon realised that I should be caching the src pointer and data pointers too. This helped explain to the compiler that the pointers wouldn’t be changing during the body of the functions and their values could remain in registers from the entire functions! I also cached flags_bitset when it was used more than once in the body of the functions - again to stop it running away to memory and back for a constant value that would never be changing.
This meant there was a lot more constant state at the start of my functions, but less unnecessary accesses during the functions themselves.
One Evening Optimizing Got Us Where?⌗
So after all the changes above, I reduced the total time taken for the citylots.json file from 3.106s to 2.548s, a nice 1.22x faster than before! The throughput going from 116.5 MB/s to 142.1 MB/s as a result.
I still don’t understand a ton of what VTune offers so I’ll have to keep tinkering, but I’m happy that it helped me identify some easy wins in my JSON parser anyway. The code for the upgrades is in two commits c4b0b90 and e38fd53 if you want to take a look.